

GEO HA – The ultimate in High Availability services
29 Oct 2021, by Slade Baylis
This month we’ve released articles detailing the different lengths we’ve gone to so that we can provide highly resilient solutions for our clients. We’ve gone into detail about how we protect our infrastructure within our data centre through our Tier IV certification. We’ve also explained how our Hyper-Converged Infrastructure protects our users from hardware caused outages. This leaves us with the next area that needs to be covered. It’s referred to as Geographical High Availability (GEO HA) and is the ultimate protection when it comes to system redundancy.
What is Geographical High-Availability (GEO HA)?
As the name suggests, GEO HA is the ability for a system to completely fall-back to running on a secondary system in a separate geographical area. The benefits of this sort of configuration are great, as it can (as long as the geographical separation is adequate enough) help isolate you from major issues that can occur such as extreme weather, fire, earthquakes, and other location based disruptions. By running two systems in parallel in two separate locations, if something like that did occur and take one site offline, then the other one would kick in and carry the load.
Though it’s a simple concept, there are a few key factors to take into consideration when looking to implement this sort of system. These can include: the distance between the facilities; the risks and benefits of them being closer or further away; or even how different system designs can affect the reliability of your infrastructure overall. Each of these factors need to be considered and weighed against the probability of threats and risks to your business.
Distance – How far is far enough?
With geographic redundancy, technically having two systems running in parallel across the street from one another would count. However, that won’t do much good if there is an act of god such as a flood that effects both sites. This is why it’s important to consider the distance between your facilities when building out the design of your infrastructure.
As with most things, there is a balance to achieve when choosing an ideal location for a secondary facility. When you increase the distance of a second site from the primary one, you reduce the risk of something like a regional natural disaster from affecting both locations. However, if it’s too far then you lose the ability to effectively mirror data in real time. When considering something like Disaster Recovery (DR) plans for this, it’s less of an issue because real-time mirroring isn’t often a major requirement, however, for geographically redundant services, this is likely to be a killer.
So what do you do? The answer is that you do a risk assessment of the probable threats facing your company and use that to determine the best approach.
Such a risk assessment should take into consideration the location of any facilities being considered, with the aim to maximise the possible distance without impacting the feasibility of the service overall. Risk factors such as earthquakes, floods, tsunamis and other natural disasters, tend to push out the distances required between facilities. If your facilities are in locations that are prone to such events, these factors should play into your decision on where to locate them. Other risk factors, such as the reliability, latency, or even cost of telecommunication links can push the case for having facilities located closer together.
Within Australia we’re lucky enough to have very low risks on the natural disaster front. Volcanoes, cyclones and tornadoes are unlikely to be a determining factor in where to place secondary or tertiary facilities. Any locations within Australia are also going to be on the same tectonic plate, so needing to protect infrastructure from earthquake risks is also less of a requirement. Even risks from more common Australian disasters such as fires are still less likely to impact multiple built up areas all at once. For most risk assessments within Australia, other less apocalyptic threats to businesses are usually the ones that need to be considered, such as the reliability of connections between the locations.
When it comes to DR plans, recommendations for secondary sites are that they should usually be located at least a couple hundred kilometres away. However as mentioned before, with most GEO HA solutions, the synchronisation requirement limits the possible distance between the sites. The technology research company Gartner1 has noted that for systems that require synchronous replication between different locations, the distance between those sites should be limited to 50 – 80kms. Research from Purdue University2 on Data Centre Site Redundancy had a similar finding, stating that it is impractical to set up synchronous replication over long distances. Different types of configurations can play a role in that determination as well, so let’s go into detail about some different types of GEO HA services and how that can affect your requirements.
Speed & Latency – Network connectivity requirements and different types of GEO HA
The maximum distances mentioned above for synchronous GEO HA services are primarily due to the physical limitation of sending data over distance. To keep data synchronised between two sites, the data needs to be sent to the second site, but confirmations also need to be sent and received back before new data can start being sent again by the primary site. For that to work, high bandwidth and low-latency connections are required. Over longer distances those types of connections aren’t just more expensive, but they also come with unavoidable higher latencies. Although synchronous GEO HA solutions are usually designed and built to utilise high-speed fibre for their connectivity, unfortunately even with the fastest connections available, the physical laws of the universe are the true bottleneck for real-time synchronisation over larger distances.
Alternative solutions do exist to Synchronous GEO HA for the exact purpose of overcoming these sorts of obstacles, however, these too come with different compromises. One alternative is to set up a form of Asynchronous GEO HA, where instead of replicating data in real time and requiring confirmation about receiving that data, the data is sent without requiring that confirmation. However, the disadvantage or drawback here is that if failover to the secondary site is required, then data may likely be lost. How impactful this potential data loss could be for a business depends, as it can range from being of no issue, all the way to it being a total show-stopper.
As Micron21 has points of presence all over the world (including Melbourne, Sydney, Amsterdam, Singapore and Los Angeles just to name a few) we are able to accommodate any type of GEO HA service that our clients require. However, within Victoria specifically, our primary Micron21 Tier IV data centre is already located 33kms away from our secondary location in the Melbourne CBD. Not only that, but we have our own secure dark fibre directly connecting these two locations. This sort of distance and connectivity is ideal for real-time synchronisation of data between two separate facilities. This is why we highly recommend Synchronous GEO HA services between these two locations for our clients with mission critical infrastructure that require 100% uptime guarantee or to those clients that need to meet rigorous DR requirements.
For connecting other sites that aren’t connected by our dark fibre, we look to Point to Point (P2P) connections to connect them. We’ve touched on the different types of P2P connections that are available in our previous article: Why more and more businesses are moving to the Cloud. To summarise, those connections can either run off existing NBN infrastructure for a cheaper solution; run off direct fibre connections such as on Ethernet Access plans; or instead be dedicated fibre MLL (Managed Lease Line) connections to provide low latency and guaranteed high speed connectivity between two sites.
Impacts on infrastructure design – “Active/Active” or “Active/Passive”
Probably the biggest decision when choosing to implement this will be which type of redundancy best fits the needs of your business. The two options to choose from when implementing this will be between either an “Active/Active” or an “Active/Passive” arrangement. The names hint at how these are set up, but we’ll break each of these down below and explain some of the differences in methodology.
Active / Active
In an Active/Active design, two systems are run in separate locations as mirrors of each other, with both systems being used as your production or “live” environments. Usually load balancers are set up in front of any servers that are used, which receive traffic and then send that traffic through to whichever server is least busy or ready to handle the request. What this means is that if one server in Location A is handling a lot of traffic and can’t handle any more, then the load balancers will know this and send any traffic to the server in Location B instead.

This has a number of benefits, as once configured, the number of servers behind the load balancers can be scaled up as needed to accommodate as much traffic as is required. It also means that the geographical aspect of the redundancy is already built in. If one of the servers at a single location goes offline, then the load balancer does its thing and sends the traffic to the servers that are still operational. With this option though, there is still one major drawback, in that both sites would still be required to be run in parallel, which in turn effectively doubles (at a minimum) the costs of your entire environment. Not only that, but this type of implementation also has effects downstream, such as on the database configurations that you will need to use.
When running systems in parallel, one of the complications to overcome is trying to keep information synchronised and consistent between each system. With regards to databases specifically, problems can arise when information is saved/written to one database, but then another associated bit of information that conflicts with that previous change is simultaneously made in another copy of that database.
For example, let’s say that you have a simple WordPress website that has its database protected via an Active/Active style Asynchronous GEO HA, meaning that separate database servers are run in parallel in separate locations. Now let’s say that one website administrator accesses and deletes a page on the website, which then gets saved to database #1. However, at the same time another administrator is also logged in and makes a change to that same page at the exact same moment, saving the changes, which coincidentally get saved to database #2.
What we have in this situation is effectively one user telling the database to remove a page, and another saying not only to keep it, but to update its contents. With regards to redundant and clustered systems, this is what’s known as “split brain” - as each part of the system disagrees with each other over which data is correct. So how do you solve this? We won’t go into too much detail here, but at a high-level the answer is through even more additional systems and complexity to keep track of which change should take priority.
As you can see, choosing to run systems in parallel can quickly increase the complexity of the required systems quite exponentially. With that being the case (and most businesses not needing that sort of scalability) the next question is whether you can get the same sort of protection without needing to dramatically increase complexity? The good news is that you can.
Active / Passive
An alternate approach is to instead look to set up an Active/Passive design. In this set up, a primary site is usually run alone and built to handle all the required traffic for a particular business system. This is definitely the easiest to implement or transition to, especially if you a transitioning from a more typical single server environment. Instead of multiple mirrored systems being run and handling production / live traffic, a secondary system is only used if the primary system is offline.
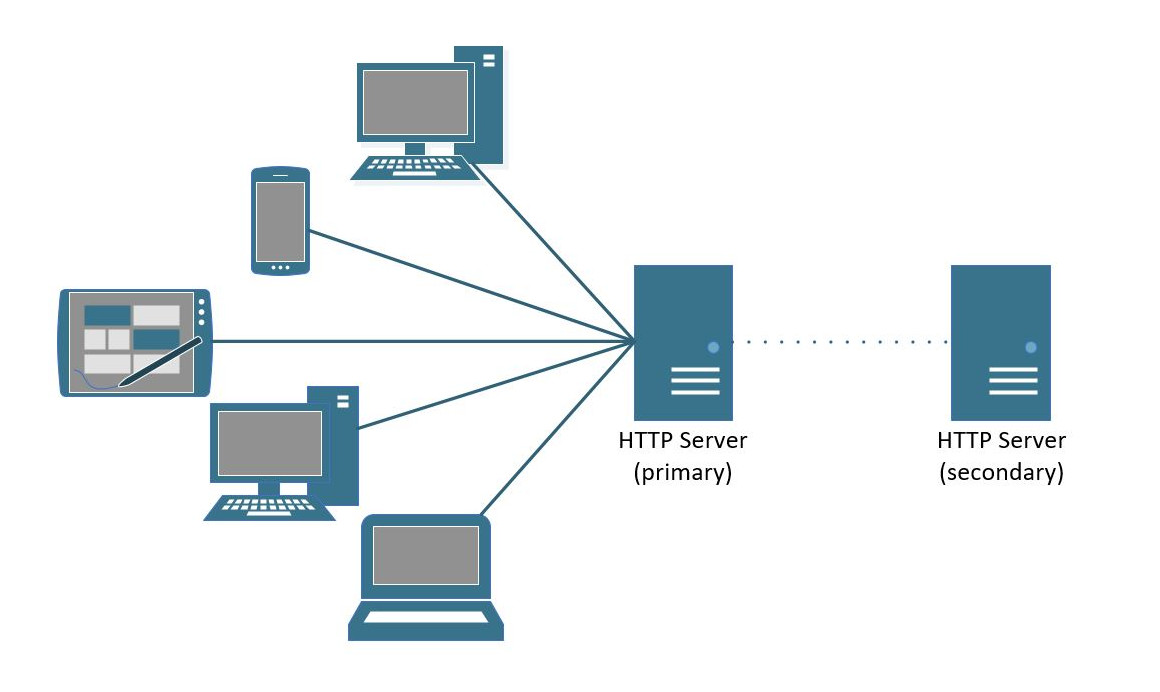
With such a setup, given secondary systems are not running in parallel, you avoid the scenario of having to double your infrastructure costs. Not only that, but you also avoid any possibility of that “split brain” scenario happening as described earlier. This is because all data is replicated in real-time to the secondary location/server, and only gets switched in the event of a failure. When/if that switch occurs, the secondary server just picks up where the previous server left off.
It should be noted, that as a secondary system needs to be switched to in the event of a failure, one of the drawbacks here is that delays are introduced in not only the detection of the issue, but also with the mechanisms to direct traffic to the secondary site. Reassuringly though, this has become less of a drawback in recent years due to the fact that failovers can be designed to occur in as little as a few seconds.
Which is better?
So with all that said, which option is the better choice? The short answer is that it will come down to the unique goals and requirements of each business. If cost is not the major limiting factor and the goal is to make the environment as scalable as possible with no delay in fail-over in the event of an issue, then an Active/Active design is the one that likely would make the most sense. It’s able to fail-over with no delay due to the load balanced design, as is able to scale up and run as many systems as needed in parallel to deal with as much traffic. For businesses that still require geographic redundancy, but are financially conscious and don’t need that scalability, then an Active/Passive arrangement is much more cost effective and simpler to maintain.
Just like with the distance consideration, each business will need to look at each factor and take into consideration the greatest risks to them specifically.
Infrastructure Reliability – Still just as important
Backup servers aren’t often thought of in forming part of an organisation’s “mission critical” infrastructure until the moment systems are down and are needed urgently. With this in mind, one thing to think about is the reliability of the infrastructure at any backup facilities that you use.
Having a primary facility certified by the Uptime Institute as a Tier IV data centre is great, but better yet is to also have a secondary location to at least be certified as a Tier III. This is because if disaster strikes and the primary location is taken off the air, then the secondary location will still have protections in place to provide reliable power, cooling, and networking to your systems. Here at Micron21, not only is our primary facility the first Australian data centre to be accredited as a Tier IV data centre, but our secondary facility is highly accredited as well, being a Tier III.
This added reliability means that if the worst was to happen and systems needed to be run out of the backup secondary facility, then you could still rest easy knowing that through the data centre infrastructure, and by replication of your servers, that your data will be protected.
The Bottom Line – Risk vs Reward
With any decision to try and protect systems from downtime, a business case needs to be made that the investments are worth the cost. Potential protections need to be weighed against the risks and threats faced by an organisation. With that said, depending on the implementation chosen, it could be that only a relatively small investment is required to give you some form of geographic redundancy. Not all options greatly increase complexity or require complete redesigns of existing systems.
If you’re interested in the different options for implementing geographic redundancy in your systems, or what the pathway would look like to get there, you can reach out to us on 1300 769 972 (Option #1) or email us at sales@micron21.com to have that conversation. We’re happy to walk you through the process and help you make a decision about what’s best for your business, taking into consideration not only the protection being offered, but also your bottom line.
Sources
1 Gartner, Use Best Practices to Design Data Center Facilities, <https://www.it.northwestern.edu/bin/docs/DesignBestPractices_127434.pdf>
2 Purdue University, Data Center Site Redundancy, <https://www.researchgate.net/publication/269231349_Data_Center_Site_Redundancy>